Frame Error
How to predictably arrive at the wrong answer despite the right facts and impeccable logic.

Today I want to explain what I call “frame errors”: a third kind of mistake, distinct from logical fallacies and empirical errors. You can get every fact right and every inference valid, and still be wrong, because your framework for reasoning about the problem is structurally inadequate.
In some sense, the idea is not new. Many other thinkers have pointed out specific instantiations of these mistakes before. However, I coin the “frame error” term1 to draw attention to the common category across these mistakes, provide tools and worked examples to help readers spot these errors when they occur, and offer advice to help readers understand and identify the meta-errors that might lead them or others to commit frame errors.
This post will go through five common classes of frame errors, with worked examples. I will start with examples that you likely have heard of before, and then end with more novel examples where I was the first person to explicitly point out such errors.
Along the way, I provide conceptual tools to model good thinking, so you can hopefully learn useful rationality and reasoning tips even if you do not buy the frame error construct.
Scope Mismatch
Can corporate greed explain inflation?
Alice: I can’t believe the price of groceries is up again! I bet it’s because of the greedy CEOs in charge of Berkeley Bowl!
Most of my readers presumably understand that Alice’s model is inadequate. But why is it wrong?
The facts are correct: The price of groceries did go up. And CEOs are known to be greedy. The internal logic also seems kinda reasonable: A greedy CEO wants to make more money, so naturally (s)he increases the price of groceries.
But of course the overall model is wrong. Not just “it’s a nuanced issue,” entirely wrong. This is because a CEO’s greed is approximately constant, but the price is varying. It’s unlikely that inflation happens because CEOs suddenly get more greedy, and prices drop because the CEOs suddenly become less greedy.
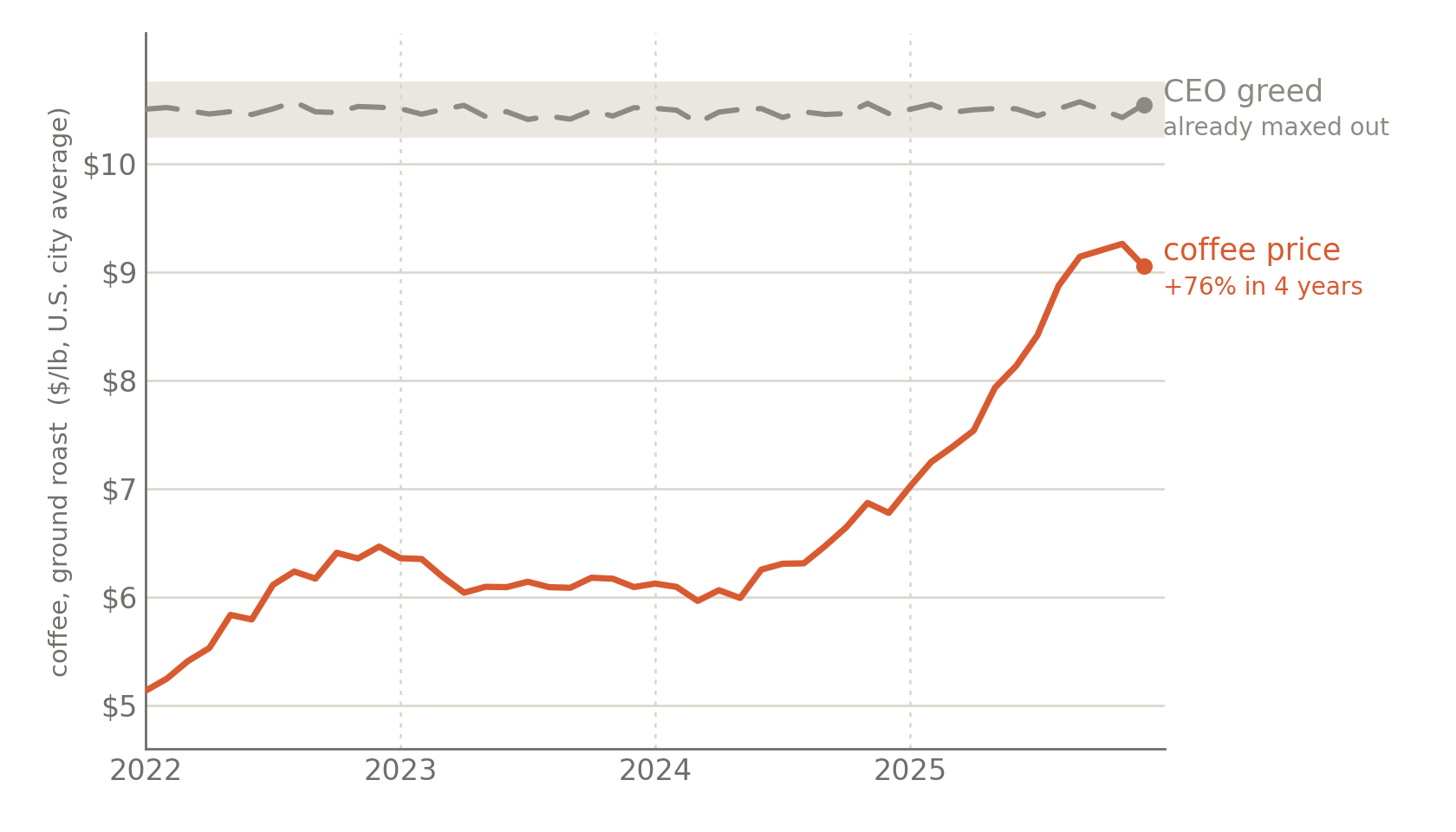
One level of abstraction up, we can form a general principle for understanding a subset of frame errors: You can’t explain a changing result by reference to a cause that’s unchanging. And its corollary: You can’t explain something that’s unchanging via reference to a variable cause.
In a broader sense, we get to an even more general principle: Every causal explanation of a contrast makes an implicit promise: the cause it points to changes wherever the effect changes. A scope mismatch, then, is when that promise is broken: when your explanation is not along the same dimension, or at the same scale, as the outcome you purport to explain.
Related: Proving too much
Two other examples of scope mismatch (that I don’t fully explain but encourage readers to work through themselves):
People sometimes use pop evolutionary psychology to explain changes in modern dating norms or other social shifts. I find it very suspicious that people are using something like evo-psych (millennia timescale) to explain 50-year behavioral shifts.
People sometimes use America-specific factors to explain global phenomena (e.g. Roe vs Wade to explain the rise and fall of crime), or global factors to explain America-specific phenomena (e.g. social media and smartphones to explain greater US political polarization). Why this is suspicious is left as an exercise to the reader.
Survivorship Bias
What do Christmas lotteries and broken bomber planes have in common?
For over two centuries, Spain has hosted an enormously popular Christmas lottery.
By total payouts, it is the biggest lottery in the world.
In the 1970s, a man went from store to store in his hometown, searching for all the tickets that ended in “48”. He bought them, and went on to win the grand prize.
Reporters later asked him why he was so keen on that number. He replied:
“Well, for 7 nights in a row, I dreamed of the number 7.”
“And, of course, 7 times 7 is 48.”
You might have seen this famous diagram already:
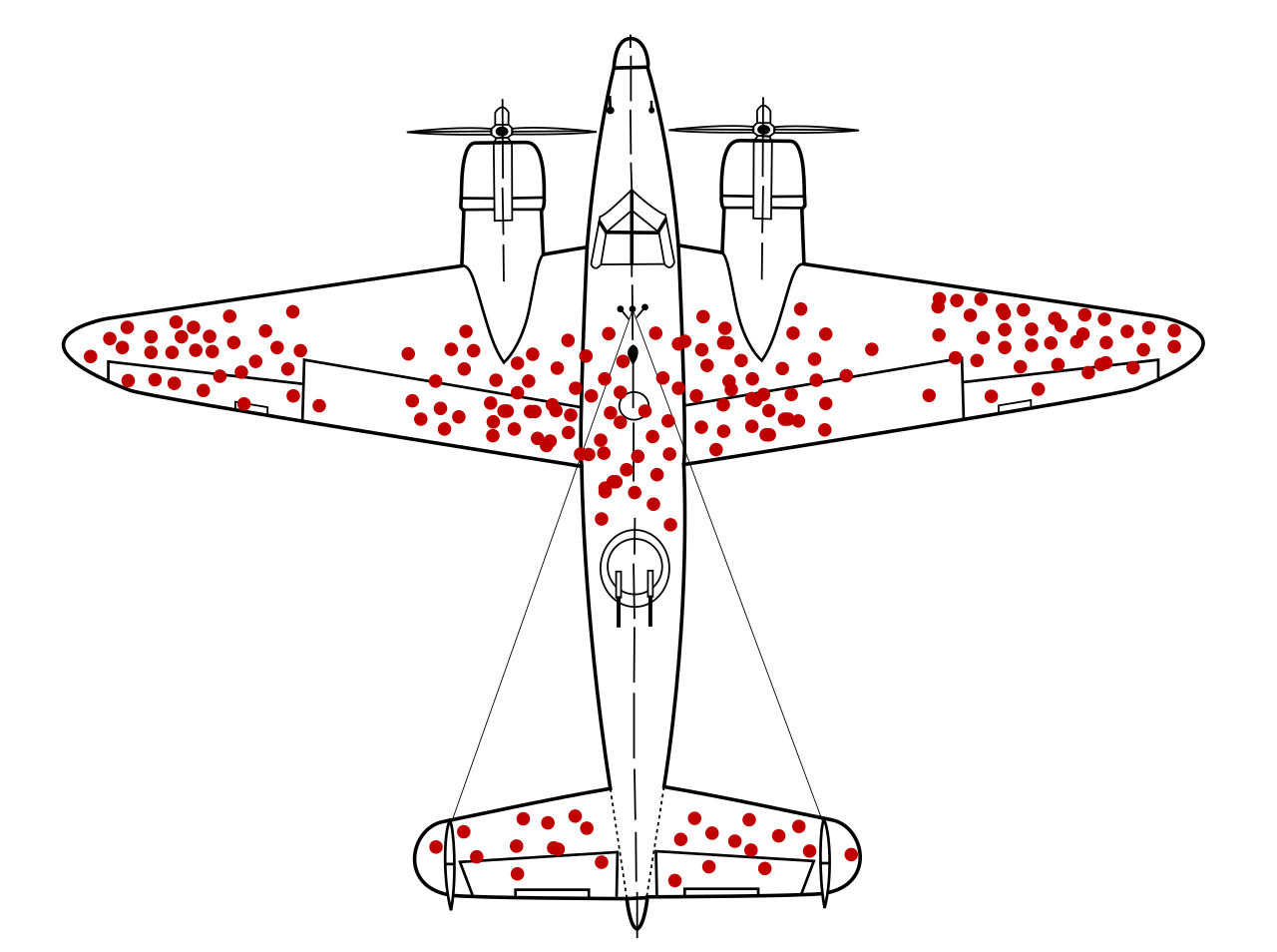
During WWII, the US military was interested in how to save their combat aircraft and pilots. They examined planes returning from missions, found bullet holes concentrated on the wings and fuselage, and minimal holes in the engine and pilot’s cockpit.
What can we learn from the data? The military proposed the obvious conclusion: add armor to the parts that get shot (wings and fuselage), don’t bother with other parts.
The consulting statistician Abraham Wald reached the opposite conclusion: Reinforce the engine and cockpit instead!
Why? Wald and others concluded that the sampling of returning airplanes had a significant (literal) survivorship bias. The planes that came back, almost by definition, survived long enough to have successfully made a return flight home. In contrast, planes that had their engines or cockpits blown out were entirely destroyed.
Survivorship bias is again a special case of frame error. Before Wald’s correction, the military looked at the evidence directly in front of them and made locally reasonable logical deductions based on their evidence, without properly considering the source of the data and how it might be systematically skewed.
Other examples of insufficiently accounting for survivorship bias include interviewing or doing studies on successful artists, sports stars, star academics, entrepreneurs etc and reporting what they said uncritically. You need to properly account for the base rate of people who tried to do the same thing and failed. It’s a bit like interviewing the Spanish lottery winner for why he got rich! Another example is naively looking at the track record of mutual funds and investing in the “best one”, ignoring that many investment companies have multiple funds and take high-variance strategies across them, silently closing under-performing ones.
The next three sections explore three other classes of frame errors, to help you understand and generalize the entire class of frame error. I use examples of errors I uncovered myself, in the hopes that reading them can be more instructive and useful than my secondhand reporting of mistakes discovered by other people.
Lossy Abstraction
When is it wrong to multiply a range of estimates about physical parameters?
The third example comes from when I first noticed, in a professional context, the importance of paying a lot of attention to the implicit limitations and assumptions of the frames that I and others use.
In particular, if you’re trying to analyze someone else’s research for correctness, it’s not enough to check just whether they’re empirically accurate about the facts that they highlighted as premises, and whether their within-model logical argument is coherent. You also need to check for whether their overall frame is structurally plausible: does their abstract picture actually map onto the real world with any degree of plausibility?
In the early 2020s, there was a resurgence of interest in cultured (lab-grown) meat. Cultured meat is grown from animal cells in a big tank, instead of being cut off an animal. It has many theoretical advantages, including reducing animal cruelty and decreased impact on climate change.
But the initial prototypes were very expensive and difficult to do well. For cultured meat to compete with conventional (factory-farmed) meat, it has to get a lot cheaper. Several groups commissioned techno-economic analyses – fancy cost-models to estimate the price per kilogram if technical advances allow various things to improve.
One particularly influential model by CE Delft, commissioned by the Good Food Institute, built a case that 9 conditions needed to (and could) improve in the near future to reach price parity with conventional meat.
I wanted to focus on two improvements in particular: a) the cells could be packed in at a much higher density (up to 2x-4x more cells per liter of tank), and b) each cell could be made bigger (up to 50%). This allowed a much higher amount of “meat” per tank, increasing utilization and decreasing cost. Each assumption is individually reasonable: CE Delft cites carefully done academic studies indicating their plausibility. And if you multiply the two improvements together, it sure seems like you get a much higher output per tank!
The problem comes when you go back from the numerical assumptions and consider the physical feasibility in the real world. Chaining the two scenarios means multiplying two factors that push in the same direction: taking up a larger and larger fraction of the tank. If you look at the actual numbers, we start with a pretty reasonable 17.5% of the tank space taken up by the cells. But if we multiply through 17.5%* 4x cells/tank * 1.5x bigger cells, we get ~100% of the tank taken up by cells! 2
This is physically and biologically implausible. Nutrients need to be transferred to the cells, and besides, cells are not perfect cubes.
The core error they made is lossy abstraction: Their simplified model of reality threw away important detail.
This is often normal and necessary. All models are wrong, some models are useful. In this case, looking at simplified models of which things are numerically possible in the literature instead of physically constructing or simulating every possibility makes a lot of practical sense.
However, you have to be careful that your lossy abstractions only throw away some details, not critical ones, and also that when you build a collective system out of different abstractions, that the combination of abstractions don’t ruin your whole project. Chaining together the different assumptions, without realizing that there was a physical constraint on the whole system, made their whole construction worthless.
(I’ve since informed them of the error, and I believe they’ve made corrections).
Another example of lossy abstractions came from the 2020 COVID-19 pandemic: Many of the top epidemiological models treated reproduction number (Rt) as unknown but fixed, and many people (alas, in the early forecasting days, myself included), treated those epidemiological models as the best we could do. The models predicted that the disease would either be suppressed early on or blaze out at herd immunity levels. Neither happened.
The reality of a pandemic that everybody knew about and everybody was reacting to meant that there was a tight behavioral feedback loop that for many months determined COVID’s actual qualitative shape (long plateaus at R≈1 rather than sharp peak and decline).
Alas, most examples of lossy abstractions aren’t as analytically clean as the CE Delft example, nor do we always have the benefits of hindsight as we did with ex post evaluations of COVID forecasting. Often in the real world, there are dubious empirical estimates and practical shortcuts you need to take to get any research or analysis done. It’s a judgment call for when throwing away information for a simplified model is just fine vs concerning but acceptable vs completely catastrophic.
But it’s often good to take a step back and ask yourself: Wait, these simplifications each individually make sense, but is there a compelling story where they make sense together? Looking at it from a different frame, does chaining these abstractions produce impossible (or at least highly improbable) results?
Post-Adjustment Inference
Why does measurement on a highly optimized variable hide apparent causality?
In the science fiction strategy game StarCraft 2, you can play one of three factions: the insectoid swarming Zergs, the technologically advanced space-elf Protoss, and the Terrans (boring humans). Competitive games are played on a variety of maps, and map designers care a lot about balance: They want every map to give equally skilled players a roughly equal chance of winning.
Some maps have what’s known as scouting pillars, a terrain feature that allows Zerg players to easily see into the territory of opponents. Naturally, many players and mapmakers believe this feature to substantially benefit the Zergs.
But is this belief true? To settle this question, a famous StarCraft 2 blogger and professor collected a bunch of data and conducted careful statistical analysis comparing Zerg win rates on maps with pillars vs. win rates on maps without them, and found that they’re about equal. Conclusion: scouting pillars don’t matter.
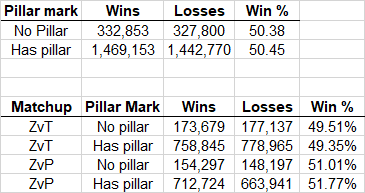
Case closed? Not quite.
Consider what the mapmakers are doing. Every map is tuned towards a 50:50 win rate. If a scouting pillar hands Zerg an advantage, the mapmakers necessarily will try to compensate elsewhere: other terrain that disadvantages Zerg, a more defensible base for Protoss and Terran, etc. So a map with a pillar would be balanced around that pillar, and a map without one would be balanced some other way.
Equal win rates don’t differentiate a world where scouting pillars don’t matter from a world where they matter a lot but map designers are good at their jobs.
Thus, we arrive at the fourth category of frame error: post-adjustment inference3. If your dataset has already been filtered or optimized around the outcome you care about, naïve statistics can make important causes look irrelevant. The effect may or may not be real, but any regressions you run can only say whether other people over- or under- adjusted for the effect, rather than how strong the actual causal element is.
Another example of post-adjustment inference. comes from people looking at college students in a university to see if SAT scores correlate with grades and graduation rates. I suspect they strongly underestimate the effects, since the SAT scores are known to admissions officials, who naturally already select on SAT scores (among other things) to decide whether to admit/not admit different students. Unless you’re very careful with your methodology, and simultaneously creative and rigorous, the default way to do this study is almost useless.
Meta-Streetlight Bias
What can statistical tools tell you about reasoning from a single data point?
Spencer Greenberg, a mathematician and social scientist, tried to answer the question “What can you learn from a single data point?”
As a mathematician and social scientist, he tried to ask it from the perspective of the statistical models he’s used to, and “realized” that singular data points can’t tell you all that much. His conclusion was that usually you can’t know much but if you know a lot about the meta-structure of your distribution (e.g. you’re interested in the mean of a distribution with low variance), sometimes a single data point can be a significant update.
This type of limited conclusion on the face of it looks epistemically humble, but in practice it’s the opposite of correct. Single data points aren’t particularly useful when you know a lot, but they’re very useful when you have very little knowledge to begin with.
If an alien sees a Ford Focus for the first time, the alien can make significant inferences on many different issues regarding Earthling society, technology, biology and culture. Similarly, an anthropologist landing on an island of a previously uncontacted tribe can rapidly learn a ton about a new culture from a single hour of peaceful interaction.4
Greenberg’s mistake, then, was using the statistical tools he’s used to from his time working in more well-established areas of quantitative social sciences and trying to fit a “single data point” into that framework. A better approach is to reason informally from actual experiences and realize that his model was missing key use cases. Alternatively, he could use information theory instead of standard frequentist statistical tools.
Ordinary streetlight bias is constraining your search for an answer to where you have clear data, rather than where the answer is most likely. It’s akin to a drunk looking for his keys under a streetlamp rather than where he dropped his keys.

Meta-streetlight bias is applying this “principle” to frameworks rather than data. You’ve fallen prey to meta-streetlight bias if you unwittingly collapse the question “How can I find an answer to my question?” into “What can my model tell me about my question?”
If you do this, your framework of inquiry is confined to the region your models can most confidently address. But often there’s more to the world, and more that you-the-human knows about the world, than are addressed most naturally by your tools.
Does meta-streetlight bias make sense to you now? If so, I encourage you to come up with another example of meta-streetlight bias and post it in the comments!
We’ve now toured five subcategories of frame error, with worked examples.
How to Avoid Succumbing to Frame Errors

Now that we’ve successfully toured five distinct categories of frame errors and worked through at least as many examples, does that mean we’re immune to frame errors in the future?
Not quite. Frame errors are a pervasive problem in human thinking (including my own). A single blog post is unlikely to fix everything! Nonetheless, here’s my advice on how to reduce frame errors in the future:
Go through a checklist. When checking for frame errors, ask:
Is the explanation varying along the same dimension as the thing explained?
What process selected the evidence I’m seeing?
Did the abstraction throw away a constraint that matters when assumptions are combined?
Has the outcome already been optimized or selected for?
Am I using the tool I have, or the tool the question needs?
The checklist is imperfect. In particular, it only helps you with seeing frame errors we already discussed, rather than help you identify new ones. Still, it’s a good start.
Actually try. Read (and listen) critically. Try to avoid getting sucked into a single frame. When someone argues for a case, try to take their facts as a given (or at least fairly plausible) but start off initially very skeptical of how they frame a problem. Run sanity checks. Can a different (even opposite!) framework or perspective explain their purported evidence equally well? What selection effects led to the facts they cited being salient to them? Etc etc.
Likewise, for your own reasoning and writing, be equally critical of your own frames, particularly in self-review/editing mode. Try to imagine what alternative frames and perspectives might say about your question, and whether they might actually make way more sense after all.
Try to get multiple perspectives on the same issue. Frame errors are more likely to be noticed by people who have a different perspective than you on the issue. Cognitive diversity is often valuable for identifying errors with your entire framework! Ideally you’re looking for informed, interested, and knowledgeable people with very different assumptions and worldviews from your own.
Simulate many perspectives in the absence of finding real ones. Now finding informed critics in general is hard enough, doubly so if you want to look for people who don’t share your overall perspectives. But in lieu of finding real people with different perspectives to critique your arguments (or in addition to them), you can attempt to simulate different perspectives. Being able to hold different perspectives in your head is directly useful for identifying your own frame errors, as well as being more careful and more generative in coming up with better frames and thinking overall.
I also recommend getting feedback from LLMs, particularly critical feedback. Frontier models (Opus 4.8, GPT-5.5 Pro, or whatever the best frontier models are at the point you’re reading this) can often simulate a critical perspective, and provide sharp critiques. They are far from perfect – in particular, they share the all-too-human foible of defaulting to a writers’ frame without checking for whether that’s the most plausible perspective, or sometimes even for correctness. But they can be a cheap and easy additional sanity check, especially if you prompt them to be critical without being nitpicky.
Note also that the situation with AI is rapidly changing. In my own internal tests Opus 4.5 (Nov 2025) was a step-change in the ability of the AIs to detect a decent fraction of frame errors, whereas previously the AIs were basically useless. ChatGPT also followed not long after. I don’t think there was a lot of progress recently, but I can easily imagine future models being much better.
Practice, practice, practice! Noticing your first novel frame error will be harder than noticing your second, and your second will be harder than the tenth. I provided some examples for you to practice with above, and you’d also likely come across many more in your readings, work, and life. My hope is that this is an analytically interesting perspective that you’d be interested in learning more about and practicing various applications thereof. Don’t just assume that reading my single blog post is sufficient for spotting such errors from now on!
Subscribe to my Substack! Finally, one of the best ways to improve as a thinker and avoid frame errors is via subscribing to my substack. And if you already subscribe, consider upgrading to a paid subscription! 100% of my paid subscribers have learned useful models from my posts.
(sharing my post with other people and encouraging them to subscribe is a good idea too).
Extensions and Future Work
Illustrating frame errors in greater detail. Some readers might be interested in taking a specific category of frame error5, and explaining it to a general audience, with worked examples. I suspect that doing this well can both produce a popular piece of writing, and be a very practically useful exercise. Plus it’d probably help you with practicing reasoning and writing skills!
Bifocal thinking. Sometimes there isn’t exactly one right perspective. Or at least one known to humans (or to you specifically). One thing you can try in those circumstances is bifocal (or trifocal, etc) thinking: where you first inhabit one (realistic) perspective on an issue, reason through it carefully, then inhabit the second perspective, reason through it equally carefully within-perspective. And then try to understand whether the right answer falls out from one or both perspectives, or something else entirely. I’ve been trying to write a full bifocal thinking post for a while now. It’s been difficult (just like this post). Alas.
The Rising Sea. This post on frame errors is about avoiding mistakes in framing, but another reason for thinking carefully about frame is that sometimes it helps you to see from a perspective that’s very, very right. Sometimes, if you look at a problem from exactly the right perspective, previously intractable problems suddenly become simple, and the solution presents itself with a beautiful crystalline clarity. Grothendieck calls this change in perspective the rising sea, and one of my dreams for rationality and conceptual posts like this one is to inspire smarter and more careful thinkers than myself to be able to see further and better and from stranger perspectives, to help them (you?) solve humanity’s daunting problems.
So go out and uncover more frame errors! Who knows? Your thinking, and perhaps humanity’s, might one day depend on it.
Appendix A: More examples
I provide a fuller list of frame errors below. For readers to think through and work out further. Unfortunately they aren’t well-explained, and I don’t intend to elaborate much. Readers are welcome to speculate in the comments however.
Scope Mismatch
Corporate greed (constant) explaining price changes (varying)
Evolutionary psychology (millennia timescale) explaining 50-year behavioral shifts
American-specific factors explaining global phenomena
Survivorship Bias
Studying successful startups to learn what makes startups succeed
Lossy Abstraction
CE Delft cultured meat: spreadsheet treats coupled physical parameters as independent, producing a physically impossible result
SIR models treating reproduction rate as fixed, dropping the behavioral feedback loop that determined COVID’s actual qualitative shape (long plateaus at R≈1 rather than sharp peak and decline)
Post-adjustment inference
StarCraft scouting pillars: Using relative win rates for maps with or without scouting pillars (theory: benefits zerg) to see if the pillars actually benefit specific factions. But mapmakers optimize for balance, so observed win rates in existing matches with/without pillars can’t provide evidence for whether pillars work.
“SAT scores don’t predict college grades” -- but colleges select on SATs, compressing the range. So the observed result can only say whether colleges select correctly for SAT scores.
Looking at college basketball for the effect of height on basketball performance.
Meta-Streetlight Bias
Spencer Greenberg treating situations where single data points are most informative as peripheral, because his statistical inference framework is a poor fit for a regime where you don’t yet have a model. This despite there in-practice being many situations where the first data point is by far the most important.
Demanding direct empirical evidence of catastrophe before believing that ASI catastrophic risk is possible.
Local-to-Global Projection
LeetCode: individually beneficial, but if everyone does it, hiring bar shifts and you’ve added a costly signal conveying no information
Standing up at a concert.
Investing money during a demand-side depression
Burning money: individual wealth decreases but remaining money appreciates
Evidence Consistent with Negation
Median Researcher Problem: fields with higher mean/median IQ replicate better. Does this imply median researchers cause higher replication rates? No, in practice higher median implies higher tail – evidence can’t distinguish “median researchers matter” from “top researchers matter”
Conflating Whether A Problem Is Important vs Who to Blame
Alice complains about a headline, Bob interrupts to tell her that actually journalists don’t write their own headlines
Kelsey Piper points out sending out potentially-pandemic hantavirus carriers to their home countries without any quarantine is bad. Tweeters assure her the WHO is not responsible.
A friend complained about a prosaic safety problem at a major AI company that went unfixed for multiple months. Someone else chimed in with saying that actually the team responsible for fixing the problem had limitations on resources like senior employees and compute, and actually not fixing the problem was the correct priority for them, etc, etc.
See Bad Problems Don’t Stop Being Bad Because Somebody’s Wrong About Fault Analysis for more.
_____________________
Humanitas update. My post on probable AI usage in the recent papal encyclical has gotten a bunch of mainstream coverage (Perfil, Snopes, Economist, Atlantic, etc). I still think it’s criminally underreported considering the stakes and newsworthiness, but understand the practicalities.
I’ve been meaning to write a followup post on it for weeks but have been stuck on a clear framing. So I’m unsure if I’d do it. I have a bunch of notes on it now though, as well as replies spread throughout various platforms. The tl;dr is that a smattering of evidence gathered over the last month, plus the lack of decisive counterarguments or negative evidence, means I’m even more confident that there was AI usage in the encyclical than when I first published my article.
I’m also more confident that undisclosed AI usage in the encyclical was bad: Relationally, I think using AI in papal writings without disclosure corrodes the relationship between the Church and her members, similar to what Pope Leo warned about with AI homilies. Epistemically, I strongly suspect the specific way they used AI decreased rather than improved the quality of their reasoning and factual awareness, particularly on the lukewarm approach to unrestricted AI construction, the incoherence of the arguments on AI consciousness, and the theology behind the whole “walls of Nehemiah” metaphor.
Anyway, thanks for all of your support, shares, new subscribers, and all the comments that helped keep this a news item! Yes, even the haters too :)General blog update: Between my day job and all the time I spent responding to follow-ups from the encyclical analysis, blogging has been really slow this month! Sincere apologies. I’ll try to do better. I do have a number of drafts that I recently took from quarter-finished to half-finished, so I’m tentatively optimistic that my posting pace will go up in the near future.
One-year anniversary coming up. The Linchpin is almost one year old (I’m also turning N years old too soon, for some N>1). From the welfare of bees to the game theory of war, from my science fiction reviews to the rising premium of life, from puns and jokes to the most important problem of our time, I’ve been delighted to be able to share my research, analysis, and hot takes with y’all. If you want to help me celebrate, please consider DMing me with one thing you’ve enjoyed reading from my blog and/or you’d like to see more of. Better yet, consider sharing your favorite post with a friend or loved one!
I tried finding older examples of this or other terms that people have used to identify this entire class of errors, and keep coming up blank. So I workshopped this term some months ago with an older Anthropic model, Claude Opus 4.6.
Ideas and writing in this post are my own.
Technically you get to 105% (ie, mathematically impossible). But even if you try to rescue it by saying that >105% is due to rounding errors, so 100% is more accurate: 100% is not possible either. Even 80% isn’t realistic due to sphere packing limits.
I don’t love the term “Post-adjustment inference.” I couldn’t think of a better one however. I used to call it “conditioning on a selected variable” and that’s not quite right either.
I like this demonstration of the “monolingual framework” in linguistics, for how much a linguist who does not share any languages with their interlocutor can learn in a single hour.
Lossy abstraction, conditioning on a selected variable, and meta-streetlight bias can all make for individually fine blog posts imo. You can see Appendix A for a fuller list, you can probably generate other subcategories of your own too.